Crawl là gì? Tại sao web crawler có vai trò quan trọng trong SEO?
Web crawlers, web spiders hoặc bot công cụ tìm kiếm đó là những khái niệm không mấy xa lạ đối với marketer hay thậm chí là người sử dụng web. Cùng 123job tìm hiểu về crawl web trong SEO nhé!
Những gì chúng ta sẽ thường nghe về web crawlers chính là nhiệm vụ duyệt website trên mạng World Wide Web là một cách có hệ thống, giúp bạn thu thập thông tin trong những trang web đó về cho công cụ tìm kiếm. Tuy nhiên, cách thức hoạt động trong web spiders ra sao và có tầm ảnh hưởng như thế nào tới quá trình SEO không phải là điều mà ai cũng biết. Để tìm câu trả lời khái niệm crawl là gì, hãy cùng tôi tìm hiểu qua bài viết của 123job dưới đây nhé!
I. Crawl là gì?
Crawl là cào dữ liệu (Crawl Data) và còn là một thuật ngữ không còn mới trong Marketing và SEO. Chính vì vậy Crawl là kỹ thuật mà những con Robots của các công cụ tìm kiếm sử dụng như là: Google, Bing Yahoo…
Công việc chính của Crawl sẽ là thu thập dữ liệu từ một trang bất kỳ. Sau đó tiến hành phân tích mã nguồn của HTML để đọc dữ liệu. Và lọc ra theo đúng yêu cầu người sử dụng hoặc dữ liệu mà Search Engine yêu cầu. crawl là gì
II. Web Crawler là gì?

Web Crawler là gì?
Trình thu thập thông tin web (hay Web crawlers), Spider hoặc bot công cụ tìm kiếm có nhiệm vụ để tải xuống và Index toàn bộ phần Content từ khắp những nơi trên Internet. Từ crawl (hay thu thập thông tin) trong cụm “Web crawlers” chính là thuật ngữ kỹ thuật sử dụng để chỉ quá trình tự động truy cập website và lấy dữ liệu thông qua một chương trình phần mềm. Mục tiêu của bot là tìm hiểu (hầu hết) thì mọi trang trên website xem chúng nói về điều gì; từ đó bạn hãy xem xét truy xuất thông tin trong khi cần thiết. Các bot này hầu như sẽ luôn được vận hành bởi những công cụ tìm kiếm.
Bằng cách áp dụng thuật toán để tìm kiếm cho dữ liệu được thu thập bởi vì web crawlers, công cụ để tìm kiếm có thể cung cấp những liên kết có liên quan để đáp ứng các truy vấn tìm kiếm trong người dùng. Sau đó, tạo danh sách những trang web cần hiển thị sau khi người sử dụng nhập từ khóa vào thanh tìm kiếm của Google hoặc Bing (hay một công cụ tìm kiếm khác). Tuy nhiên, thông tin Internet lại vô cùng rộng lớn và khiến cho người đọc khó mà biết được liệu tất cả thông tin cần thiết đã được index là đúng cách hay chưa?
III. Cách bot công cụ tìm kiếm trong crawl website
Internet không ngừng thay đổi cũng như mở rộng. Vì không thể biết tổng số website có trên Internet và Web crawlers bắt đầu từ một danh sách những URL đã biết. Trước tiên, chúng thu thập dữ liệu webpage tại những URL đó. Từ các page này, chúng sẽ tìm thấy những siêu liên kết đến nhiều URL khác nhau và thêm các liên kết mới tìm được vào danh sách các trang cần phải thu thập thông tin tiếp theo.
Với số lượng lớn những website trên Internet có thể được lập chỉ mục để tìm kiếm và quá trình này có thể diễn ra gần như là vô thời hạn. Tuy nhiên, web crawler sẽ được tuân theo một số chính sách nhất định giúp cho nó có nhiều lựa chọn hơn về việc nên thu thập dữ liệu của trang nào, trình tự thu thập thông tin ra sao với tần suất thu thập lại thông tin để kiểm tra cập nhật nội dung.
Tầm quan trọng tương đối trong mỗi trang web: Hầu hết những web crawlers không thu thập toàn bộ thông tin có sẵn khi công khai trên Internet và không nhằm bất cứ mục đích gì; thay vào đó thì chúng quyết định trang nào sẽ thu thập dữ liệu đầu tiên và dựa trên số lượng nhiều trang khác liên kết đến trang đó, lượng khách truy cập mà trang đó nhận được và những yếu tố khác để biểu thị khả năng cung cấp thông tin quan trọng trong trang.
Lý do đơn giản chính là nếu website được nhiều trang web khác trích dẫn và có nhiều khách truy cập thì chứng tỏ nó có khả năng chứa nhiều thông tin chất lượng cao và có thẩm quyền.
Revisiting webpages:
Là quá trình mà web crawlers truy cập lại những trang theo định kỳ để index các phần content mới nhất bởi vì content trên Web liên tục được cập nhật, xóa hay di chuyển đến những vị trí mới.. crawl là gì
Yêu cầu về Robots.txt:
Web crawlers cũng quyết định những trang nào cũng sẽ được thu thập thông tin dựa vào giao thức robots.txt (còn được gọi là robot giao thức loại trừ). Trước khi thu thập thông tin một trang web thì chúng sẽ kiểm tra tệp robots.txt do máy chủ web trong trang đó lưu trữ. Tệp robots.txt chính là một tệp văn bản chỉ định những quy tắc cho bất kỳ bot nào truy cập vào trang web hay ứng dụng được lưu trữ. Những quy tắc này xác định các trang mà bot có thể thu thập nhiều thông tin và các liên kết nào mà chúng có thể theo dõi.
Tất cả những yếu tố này có trọng số khác nhau tùy vào các thuật toán độc quyền mà mỗi công cụ tìm kiếm để tự xây dựng cho các spider bots của họ. web crawlers từ những công cụ tìm kiếm khác nhau sẽ hoạt động hơi khác nhau, mặc dù mục tiêu cuối cùng là giống nhau: cùng tải xuống và index nội dung từ những trang web.
IV. Tại sao web crawlers được gọi là ‘spiders’?
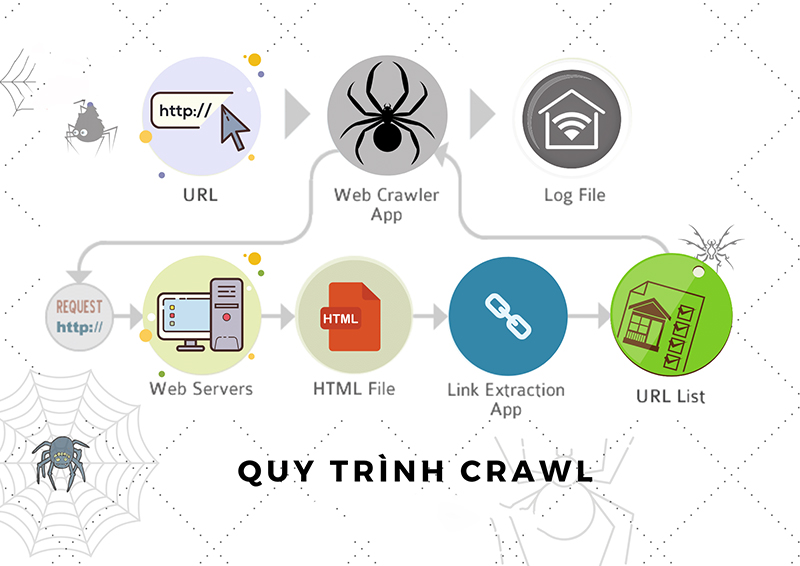
Quy trình của Crawl
Internet, hoặc ít nhất là phần mà hầu hết người sử dụng truy cập, còn được gọi là World Wide Web – trên thực tế, đó là nơi để xuất phát phần “www” của hầu hết những URL trang web. Việc gọi các bot của công cụ tìm kiếm đó là “spiders” là điều hoàn toàn tự nhiên, bởi vì chúng thu thập dữ liệu trên khắp các trang Web, giống như những con nhện bò trong mạng nhện. crawl là gì
V. Sự khác biệt giữa web crawling và web scraping
Data scraping, web scraping hay content scraping chính là hành động một bot tải xuống nội dung có trên một trang web mà không được cho phép bởi chủ website, thường đối với mục đích sử dụng nội dung đó cho mục đích xấu.
Web scraping thường được target nhiều hơn trong web crawling. Web scrapers có thể chỉ theo dõi một vài trang websites cụ thể, trong khi web crawlers sẽ được tiếp tục theo dõi những liên kết và thu thập thông tin các trang liên tục.
Bên cạnh đó, web scraper bots có thể qua mặt về máy chủ dễ dàng, trong khi web crawlers, đặc biệt là từ những công cụ tìm kiếm lớn, sẽ tuân theo tệp robots.txt và gia hạn các yêu cầu trong chúng để không bị đánh lừa máy chủ web.
VI. Cách để Google Crawling tất cả nội dung quan trọng của bạn
Bây giờ bạn đã biết một vài chiến thuật để đảm bảo trong trình thu thập công cụ tìm kiếm để tránh xa nội dung không quan trọng của bạn. Hãy tìm hiểu về cách tối ưu hóa có thể giúp cho Googlebot tìm thấy những trang quan trọng của bạn.
Đôi khi một công cụ tìm kiếm cũng sẽ có thể tìm thấy các phần của trang web của bạn thông qua cách thu thập thông tin. Tuy nhiên các trang hoặc phần khác có thể bị che khuất bởi vì lý do này hay lý do khác. Điều quan trọng đó là đảm bảo rằng những công cụ tìm kiếm có thể khám phá tất cả nội dung mà các bạn muốn lập chỉ mục và không chỉ trang chủ của bạn.
Xem thêm: Google Analytics là gì? Hướng dẫn sử dụng Google Analytic hiệu quả
VII. Bạn có đang dựa vào những hình thức tìm kiếm?
Googlebot cũng sẽ gặp khó khăn khi quét dữ liệu vì những hình thức tìm kiếm. Một số cá nhân tin rằng nếu như họ đặt Search Box trên trang Web của họ và công cụ tìm kiếm sẽ có thể tìm thấy mọi thứ mà khách truy cập của họ tìm kiếm. Nhưng điều này có thể ngăn việc trong Googlebot thu thập dữ liệu trên trang Web. Vì vậy bạn hãy cân nhắc kỹ lưỡng trong việc cài đặt Search Box của Website.
Hidden Text truyền tải những nội dung qua phi văn bản
Không nên sử dụng những hình thức đa phương tiện ( như là hình ảnh, video, GIF,…) để hiển thị văn bản mà các bạn mong muốn được lập chỉ mục. Mặc dù những công cụ tìm kiếm đang trở nên tốt hơn trong việc nhận dạng hình ảnh, tuy nhiên không có gì đảm bảo họ sẽ có thể đọc và hiểu nó. Thế nên, tốt nhất là thêm văn bản ở trong phần đánh dấu của trang Web của bạn.
VIII. Công cụ tìm kiếm có thể theo dõi để điều hướng trang web của bạn?
Googlebot đã khám phá trang Web thông qua những Backlink từ các trang Web khác trỏ về hay hệ thống Internal Link của những trang trên tổng thể Website.
Nếu bạn đã có một trang mà bạn mong muốn những công cụ tìm kiếm tìm thấy tuy nhiên nó không được liên kết đến từ bất kỳ trang nào khác, thì nó gần như là vô hình. Ngoài ra, một số Website mắc sai lầm sẽ nghiêm trọng trong việc cấu trúc điều hướng của họ theo nhiều cách không thể tiếp cận với các công cụ tìm kiếm. Điều đó làm cản trở về khả năng được liệt kê trong kết quả tìm kiếm.
IX. Kết luận
Trên đây là đầy đủ thông tin chi tiết về khái niệm Crawl là gì và cách tối ưu hóa quá trình Google thu thập các dữ liệu trên Website. Vốn rất quan trọng đối với những doanh nghiệp cung cấp dịch vụ SEO. Khi bạn đã đảm bảo trong trang web của mình được tối ưu hóa cho quá trình Crawling dữ liệu, việc tiếp theo trong doanh nghiệp đó là đảm bảo nó có thể được lập chỉ mục (Indexing).
Bài viết nhiều người đọc
Nhân viên thu ngân là gì? Bạn đã biết chưa?
Nhân viên phục vụ là gì? Bí quyết trở thành nhân viên phục vụ chuyên nghiệp
Những kỹ năng cần thiết của kiến trúc sư trong phát triển sự nghiệp
Shipper là gì? Những khó khăn ít ai biết về công việc shipper
Cẩm nang kinh nghiệm làm shipper cho sinh viên làm thêm
Shipper nên lựa chọn hãng giao hàng nào để có thể làm việc?
Trợ lý và thư ký khác nhau như thế nào?
Khám phá việc làm nhân viên nhập liệu từ A tới Z
123job.vn - Trao cơ hội cho hàng triệu người với những công việc mơ ước với môi trường làm việc chuyên nghiệp và mức lương tốt nhất.
Với sứ mệnh: Cung cấp các thông tin việc làm, review công ty hấp dẫn, dịch vụ tư vấn tuyển dụng xác thực và chất lượng cho nhà tuyển dụng và người lao động, chúng tôi luôn tận tâm tận lực, không ngừng sáng tạo nhằm đem lại chất lượng dịch vụ hàng đầu, giúp tất cả mọi người có được một công việc phù hợp nhất.
Tự hào: Là trang tuyển dụng uy tín, là cầu nối của hàng triệu người tìm việc và nhà tuyển dụng.
- Luôn chủ động và sáng tạo, lấy công nghệ làm nền tảng cốt lõi để phát triển dịch vụ.
- Chuyên nghiệp & tận tâm với khách hàng và người tìm việc bằng những dịch vụ tốt nhất.
- Làm việc chính trực, tuân thủ các nguyên tắc đạo đức, không vụ lợi cá nhân và luôn đặt lợi ích của công ty lên hàng đầu.
Nếu bạn đang muốn kết nối với những nhà tuyển dụng uy tín hàng đầu Việt Nam, đừng ngần ngại hãy TẠO CV NGAY để tăng gấp 5 lần cơ hội có được công việc với mức lương tốt nhất nhé!
